https://blog.infected.systems/posts/2024-12-04-hugs-of-death/
1 Like
fully agreed with the sentiments of the post, and as a professional webdev who does often have to interact with services hosted by the Big Platforms, i can confidently say that i regret doing so more often than not.
sometimes you need to prepare to scale - sometimes you just need it to work. frankly, if one of my blogs got enough traffic to crash the server, that is a very good problem to have. especially if you’re just doing something personal or niche, there’s no reason to try to build a system that can metabolize a hundred thousand people visiting your shit at once on all seven continents on earth - it mostly isn’t ever worth the trouble
3 Likes
While I remain tempted to redirect HN referrers to something truly vile and thoroughly NSFW, it’s not because I’m worried about getting a “hug of death”, or what used to be called the Slashdot Effect.
I dislike most of HN’s commentariat for ideological reasons, but the plain fact is that even if one of my posts makes the front page on HN, nobody is going to die if starbreaker.org goes down for a couple of hours. Nor am I going to lose thousands or even millions of dollars in revenue to downtime. Therefore, maintaining 99.999% availability isn’t a priority for me.
2 Likes
They’ll have to pry “slashdot effect” from my cold, offline hands. Relabeling it as the “digg effect” or whatever else is an affront to my memory!
I prefer “getting FARKed”, since that’s the site I used to frequent instead of Slashdot.
1 Like
It’s funny that it was specifically down to an IPv4-IPv6 thing which related to the topic of the post that got all the traffic.
It’s also particular to how indies use cloud services in different ways than firms: they’re more likely to use a single instance in a single region with no load balancer or CDN.
I’d be more worried about an unexpectedly high bill, really. Those cloud providers often bill by traffic and there won’t be any cap by default.
The easiest way to think about it is for it to be somebody else’s problem: with static file shared hosting that doesn’t bill bandwidth.
1 Like
Yeah, somebody using Netlify found that out the hard way and got nailed with a $104,000 bill.
This is one reason I’ve been using Nearly Free Speech; if my deposited funds run out they just shut down the site until I deposit more money. And they email me when there’s less than $5 in my account.
2 Likes
Yeah, I’m less concerned about downtime and more concerned about bandwidth and running up a bill I can’t pay due to an unethical AI scraper. Haven’t made the switch to Nearly Free Speech, though…
Every time I hear about the HN hug I’m left wondering if I’m just lucky or if my setup is just incredibly great without me realizing it.
I’m no sysadmin, I barely know what I’m doing when it comes to servers. I run a roughly 5$/month VPS with no CDN or load balancer or any of that stuff.
I only notice the HN hug if I happen to check the server logs because I notice the massive spike. All the various VPS I use have been online for years at this point with no downtime.
But my site is also stupid lightweight and file based so maybe that’s why? I mean, serving 10k users a 5kb page is obviously way different than serving a 5MB one with a bunch of assets and what not.
2 Likes
Perfect timing!
Got an email that started with:
I just came across a blog post of yours on hacker news
Sure enough, someone posted something I wrote and it’s now sitting on the front page. These are the stats from my VPS in the last 24 Hours
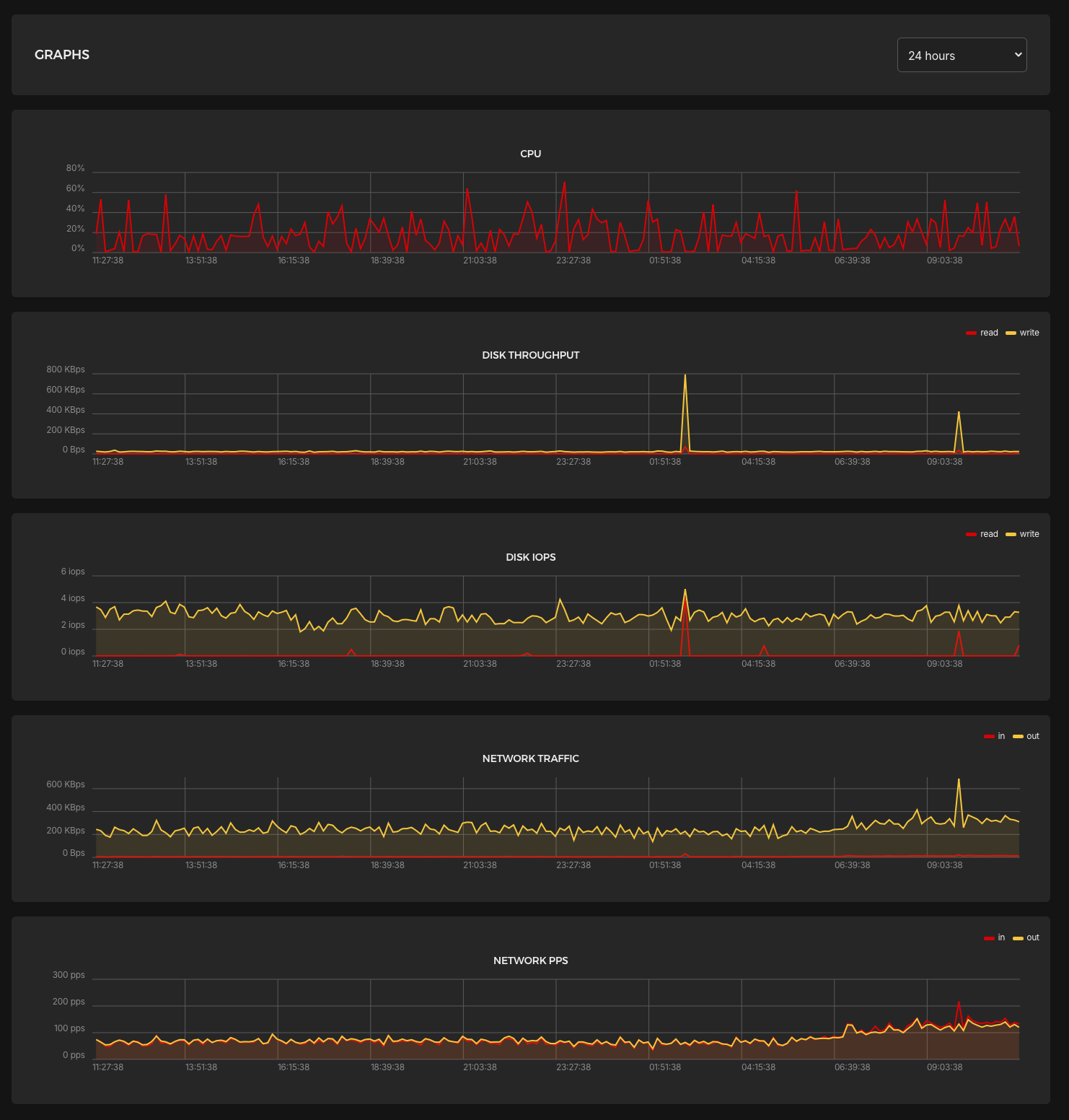
If it wasn’t for the email i’d never have noticed it.
1 Like
It turns out that a lot of people have strong opinions on ads.
It seems so ahah
Also, so many bad takes as usual. But I got a few nice emails and that’s all I care about.
3 Likes
Yeah, there are a lot of clowns on HN.
1 Like
Don’t worry about hackernews, you should think about whether your VPS can handle that I shared your post.
On a serious note, I probably wouldn’t even notice it if happened to my website. I don’t have any tracking enabled, save for the .log file that the OpenBSD httpd web server writes to. And I’ve never looked at it. In fact, my site went down for hours as I was moving from one host to another recently. So a little downtime is not something I worry too much about.
2 Likes
Ah, I’ll let you know if I see the Lars Hug ahah
Jokes aside I can check inside the server logs and see how many people you sent me (in theory)
I honestly only look at the logs to check fun stuff like this one. For all I know everything I see in the logs could be bots so why even bother checking regularly
1 Like
There is also the “Mastodon stampede” that will knock out a LAMP stack when thousands of servers all try to generate an opengraph preview card all at once.
A sensible caching configuration ought to mitigate this. Approaches like “hydrating” mostly-static pages with dynamic parts would also probably work. Neocities users know how to do this because it’s their only option!
2 Likes
I was so tired of that that I ended up blocking all mastodon instances from asking my site for meta information. It’s such a dumb implementation of a feature.
“hug of death” is a good non-specific term at least. you just add a given sitename prior to it, and boom, reddit hug of death! hn hug of death! 32bit cafe hug of death, somehow? intriguing!
3 Likes
Hell, you could replace most of these with “Big Tech hug of death”.
1 Like
I’m starting to wonder though, at what point do you think one should start thinking about this as a personal responsibility?
My blog is nowhere near big enough to be a concern obviously but I do know that if I link to something some hundreds of people might go to that link.
You scale that up and at some point a single blog might start to become a problem. What should you do in that case? Not link to something? Should people have a policy on their site about this stuff? Or should we just accept that getting hugged to death is part of being online with a personal site?